


你知说念吗,让 Agent记着你的形态险峻文、时间决策和责任习尚,这件事完全不错不花一分钱、不连任何云工作、数据全留在我方电脑上就作念到。
每次怒放 Hermes 或 OpenClaw 新建会话,你都得再行讲解一遍形态用了什么框架、前次修 MCP 断线用的什么号令、为什么选 jose 而不是 jsonwebtoken。不是模子不够机灵,是险峻文窗口骨子上是"一次性"的——会话驱散,挂牵也随着清零。
开源社区早就盯上了这个问题。往日一年里,至少有六款成心针对 Agent挂牵扩张的开源器具冒了出来——完全开源免费、完全不错腹地部署、何况功能少量不骗取。
这篇著作就带你把这六款器具一一看一遍:它们怎样责任的、怎样装置成就、各自有什么所长和短板、你的场景最合适哪个。
先搞清你需要哪种"挂牵"
在聊具体器具之前,有一个要害分歧要先证据白——AI 助手需要记的东西,其实分两种:
类型问的问题例如行动/情节挂牵"我(Agent)前次怎样操作的?""前次开拓 MCP 断线用了什么号令?"学问/文档挂牵"我知说念什么贵寓?""GEO 写稿法式第三条怎样说的?"
前者纪录 Agent 的操作历史,后者检索已有的文档学问库。两类需求合适不同的器具,最佳的决策是搭配使用。
一、行动挂牵类:让 Agent 记着"我作念过什么"
1. agentmemory
GitHub:rohitg00/agentmemory(23,000+ Stars,MIT 公约)
agentmemory 是当今祥和度最高的 AI 编程 Agent 执久挂牵决策。它的中枢卖点就一个词:零抑止。Agent 履行器具调用时,它通过 Hook 机制自动静默拿获整个操作,你什么都毋庸管。
责任旨趣
每次 Agent(Hermes、Claude Code 等)调用器具时,agentmemory 拿获一条 Observation 纪录。
这些纪录流程 iii-engine 压缩后存入腹地 SQLite。下次新建会话时,agentmemory 自动检索联系历史险峻文并注入进去。
检索机制:三流和会
这是 agentmemory 最值得细说的地点。它不是浮浅地作念要害词搜索——它同期跑三路:BM25 全文检索、向量语义检索、学问图谱遍历,临了通过 RRF(Reciprocal Rank Fusion)和会排序。在 LongMemEval-S 基准测试上,调回率作念到了 95.2%,而 mem0 只消 68.5%、Letta/MemGPT 是 83.2%。
典型使用场景
记着形态里用了哪个库以及为什么选它("为什么用 jose 而不是 jsonwebtoken")
跨会话不息前次没作念完的任务
自动祛除一经踩过的坑("这个 CORS 问题前次怎样处治的")
多个 Agent 实例(Hermes + OpenClaw)分享合并份时间决策历史
优点
零抑止,完全自动拿获,不需要手动保重担何文献
零外部依赖,纯 SQLite,不需要 Docker 或极度工作
多 Agent 分享,一个工作同期工作多个 Agent 实例
MIT 公约,完全腹地运行,不连任何外部 LLM
调回精度在同类器具中最高(95.2% R@5)
❌ 短处
天博体育(TianboSports)官网仅对接 Coding Agent,不合适通用 LLM 利用的用户画像场景
默许 Embedding 模子(all-MiniLM-L6-v2,80MB)对中语相沿一般,中语形态提出替换为 Qwen3-Embedding
依赖 iii-engine 版块锁定(v0.11.2),升级需严慎
值得看护的是,agentmemory 的挂牵写入和检索均不调用任何 LLM,完全腹地规划。这是它和 mem0 最大的区别之一。
2. mem0
GitHub:mem0ai/mem0(41,000+ Stars,Apache 2.0)
mem0 和 agentmemory 定位不同。它面向的是 LLM 利用(聊天机器东说念主、个性化助手),从对话内容中自动索求结构化用户事实——偏好、习尚、身份信息——构建用户画像。
责任旨趣
每次对话驱散后,mem0 调用 LLM 分析对话内容,索求出近似"这个用户可爱 TypeScript、不可爱冗余凝视"的事实,写入向量数据库。下次对话时检索注入,已矣个性化。
典型使用场景
记着用户的编码作风偏好("可爱函数式作风,毋庸 class")
跨会话保执用户画像("这个用户在作念 Electron 形态")
构建面向终局用户的个性化 AI 产物
优点
自动从对话索求事实,无需手动追忆
相沿 MCP 接入,可集成到 Hermes/OpenClaw
生态最纯熟(YC 投资,14M+ 下载)
❌ 短处
部署较重:需要 Qdrant 或 Chroma 等向量数据库(极度 Docker 工作)
每次写入挂牵时必须调用 LLM 索求事实(相沿腹地 Ollama/oMLX)
与 agentmemory 定位不同,不合适替代后者
二、学问检索类:让 Agent 找到"我存了什么"
3. QMD
GitHub:Shopify CEO Tobi Lütke 发起,OpenClaw 生态中枢器具(MIT 公约)
QMD(Quick Markdown Database)是专为 OpenClaw / Hermes 打算的腹地 Markdown 学问库搜索引擎。它处治的问题不是"前次怎样作念的",而是"我的条记里写了什么"。
责任旨趣
QMD 对你 workspace 目次下的整个 Markdown 文献建立双索引——BM25 倒排索引加向量索引——查询时两路打分,再经 Reranker 和会排序,复返最联系的文本段落。三个腹地模子自动下载,悉数约 2.3GB:
模子扮装默许模子大小Embeddingjina-embeddings-v3 (GGUF)330 MBRerankerjina-reranker-v2-base-multilingual (GGUF)640 MBQuery Expansion内置小 LLM1.3 GB
中语形态可替换为 Qwen3-Embedding GGUF 以优化检索成果。
典型使用场景
搜索时间条记、架构打算文档("这个接口的打算原则")
检索 GEO 写稿法式("SEO 要害词密度条款")
查找已有代码片断的讲解("Aliyun OSS 签名上传的备注")
看成 NotebookLM 的腹地替代决策
优点
专为 Markdown 优化,OpenClaw 生态原生相沿
三模子管线检索质地高(BM25 + 向量 + Reranker)
完全离线,模子下载一次后永远缓存
相沿多 Collection,不同形态学问库相互远离
❌ 短处
需要手动保重 Markdown 文献,澳门人·威尼斯官网(中国)登录入口不自动拿获 Agent 行动
初次 qmd embed 下载约 2.3GB 模子
对代码库和非 Markdown 文献相沿有限
Query Expansion 阶段会调用内置小 LLM,加多查询蔓延约 300ms,无需极度成就。
4. Cognee
GitHub:topoteretes/cognee(Apache 2.0)
Cognee 从根蒂上区别于 QMD:它不作念文档不异度检索,而是从文档中索肄业识图谱,汇报"A 和 B 有什么关系"这类推感性问题。
责任旨趣:ECL 三阶段
Extract:识别文档中的实体(模块、东说念主员、想法、时间名词)
Cognify:用 LLM 计算实体间关系(依赖/影响/属于),构建三元组
Load:写入腹舆图数据库(默许 NetworkX 内存图,可换 Neo4j)
查询时通过图遍历而非向量不异度,能已矣多跳推理。比如" MCP 断线 → 影响哪些 Agent → 这些 Agent 依赖哪些工作"——这种问题 QMD 是答不了的。
典型使用场景
和会代码库中模块之间的依赖关系
计算"A 功能崩溃会影响哪些下贱"
从多篇文档中抽象出共同论断
分析系统架构的影响链路
优点
❌ 短处
索引速率慢,每篇文档都要跑 LLM 索务实体,约比 QMD 慢 5–10 倍
查询蔓延较高(图遍历 200ms–2s)
对浮浅的文档检索需求属于"杀鸡用牛刀"
实体索求是 Cognee 的中枢神气,必须调用 LLM,但相沿腹地 Ollama/oMLX,完全免费。
三、时序与用户画像类
5. Zep(Community Edition)
GitHub:getzep/zep(Apache 2.0)
Zep 专注于时序感知挂牵——它不仅记着"说了什么",还记着"什么时候说的、这条信息是否已被更新掩盖"。2026 年与 LangGraph 深度整合后祥和度大增。
典型使用场景
"上周我说用 Redis,这周改成了 SQLite,以最新的为准"
跟踪形态决策的演化历史(某个时间决策阅历了几次变更)
需要时刻线推理的复杂对话系统
优点
时序跟踪是稀奇才能,其他器具都莫得
2026 年 LangGraph 官方集成,生态好
企业级打算,相沿大限制部署
❌ 短处
需要 Postgres + pgvector,部署相比重
对纯 Coding Agent 场景价值有限(agentmemory 更合适)
6. TencentDB Agent Memory
GitHub:Tencent/TencentDB-Agent-Memory(Apache 2.0,2026 年 4 月开源)
腾讯开源的四层渐进式挂牵架构,完全 SQLite 腹地运行,对中语内容和国里面署环境针对性优化。
四层架构
层级内容L0 原始对话全量保存L1 原子挂牵自动索求事实、偏好、要害敛迹L2 场景分块按形态聚类,险峻文精确调回L3 用户画像踏实个性化默契
典型使用场景
中语环境的用户偏好挂牵
国内信创/独到化部署场景
替代 mem0 的纯腹地中语决策
优点
零外部依赖,纯 SQLite
中语分词和语义和会针对性优化
Apache 2.0,国内社区保重活跃
❌ 短处
生态相对较新,MCP 器具数目少于 agentmemory
文档和社区资源主要为中语
L1 层索求事实需要运动 LLM(可成就腹地 Qwen3)
对比总览
功能与时间对比
器具定位写入方式检索方式腹地依赖需要 LLM开源公约agentmemoryCoding Agent 行动挂牵自动 HookBM25+向量+图谱SQLite(零依赖)不需要MITmem0用户画像/个性化自动索求向量检索需要 Qdrant需要Apache 2.0QMDMarkdown 文档检索手动写文献BM25+向量+Reranker腹地 GGUFQuery ExpansionMITCognee学问图谱/关系推理自动索求三元组图遍历腹地(需 LLM)必须Apache 2.0Zep CE时序感知挂牵自动索求向量+时序索引Postgres+pgvector需要Apache 2.0TencentDB AM中语用户画像自动索求向量检索SQLite(零依赖)L1 层需要Apache 2.0
腹地部署友好度
器具磁盘占用极度工作部署难度agentmemory~80–600 MB(Embedding)污秽简QMD~2.3 GB(3个GGUF模子)污秽简TencentDB AM极小(SQLite)污秽简Cognee~500 MB SDK + LLM已有 Ollama/oMLX浮浅mem0~1 GBQdrant(Docker)中等Zep CE~2 GBPostgres + pgvector(Docker)较复杂
检索精度对比
器具评测得分备注agentmemory95.2%(LongMemEval-S R@5)三流和会检索Letta/MemGPT83.2%供参考mem068.5%不同场景打算,不完全可比Zep75.14%(LOCOMO)不同基准,侧重时序推理
各器具使用不同评测基准,数字不行凯旋横向相比,仅供参考。
怎样选?场景决策树
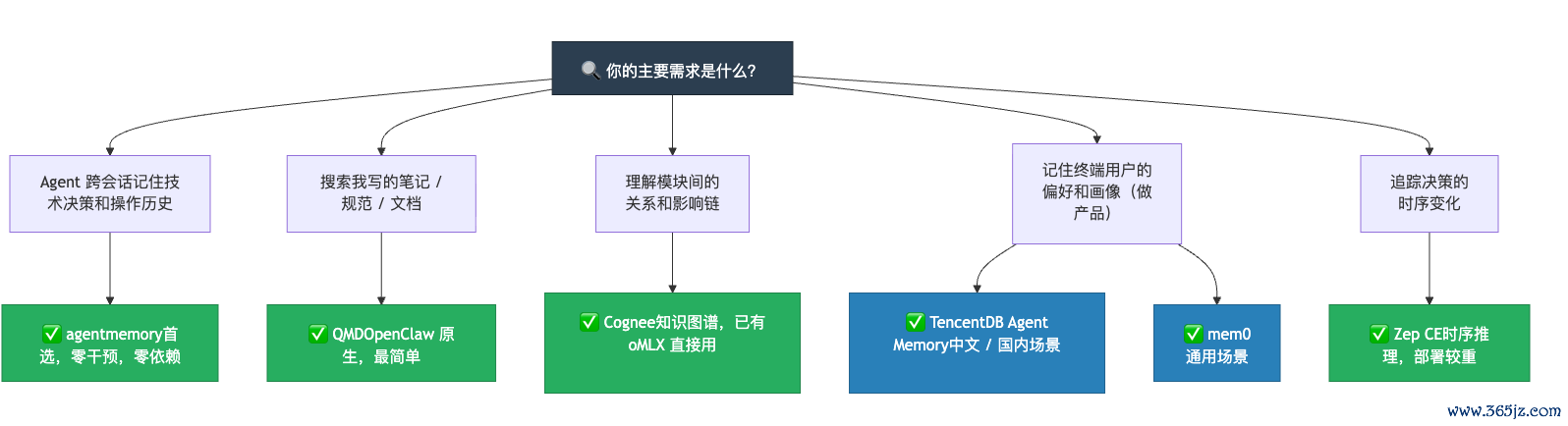
保举的组合决策
关于 OpenClaw / Hermes 的个东说念主开发者,仙踪问说念团队在推行部署中考证了一个三层搭配决策:
第一层用 agentmemory,自动拿获 Agent 行动历史,零抑止,关掉无论它,它肃静在后台纪录整个的时间决策和操作。
第二层用 QMD,把蹙迫的时间条记、形态法式写成 Markdown,Agent 就能随时检索这些学问库。两个器具都看成 MCP Server 挂载,互不干扰,一个管"作念过什么",一个管"知说念什么"。
形态复杂度上去之后——代码库有好几个微工作、模块之间依赖关系复杂——再加 Cognee,引入图谱推理才能。三层就王人了:行动挂牵 + 文档检索 + 关系推理。
# ~/.hermes/config.yaml
mcp_servers:
agentmemory:
command: "npx"
args: ["@agentmemory/mcp"]
qmd_search:
command: "qmd"
args: ["serve", "--port", "7333"]
归根结底,Agent的"失忆症"不是时间作念不到,而是艰难一个中间层——一个能在会话除外执久化学问、跨会话注入险峻文的挂牵系统。开源社区给的这六款器具,即是在补这一层。它们一说念开源免费、完全不错腹地运行、数据留在我方的机器上。
还没下载使用Openclaw和Hermes, 快来仙踪问说念·智能助手启动你的智能之旅吧!



附录:要害术语
MCP(Model Context Protocol):Anthropic 推出的开放公约,允许 LLM 通过步履接口调用外部器具和工作。agentmemory、QMD 等器具均提供 MCP Server,可凯旋挂载到 Hermes/OpenClaw
BM25:经典全文检索算法,基于词频和逆文档频率打分,速率快
向量检索:将文本回荡为高维数字向量,基于语义不异度检索
Reranker:对初步检索摒弃再行打分排序的模子
学问图谱:以节点(实体)和边(关系)表奉告识的图结构,相沿多跳推理
LongMemEval-S:成心评测 AI Agent 跨会话恒久挂牵才能的步履基准测试集澳门人·威尼斯官网(中国)登录入口
 备案号:
备案号: